
Part III. Spatial interactions on a grid
III-3. Extension to any number of strategies
1. Goal
Our goal here is to extend the model we have created in the previous chapter –which accepted games with 2 strategies only– to model (2-player symmetric) games with any number of strategies.
2. Motivation. Spatial Hawk-Dove-Retaliator
The model we are going to develop in this chapter will allow us to explore games with any number of strategies. Thus, we will be able to model games like the classical Hawk-Dove-Retaliator (Maynard Smith, 1982, pp. 17-18), which is an extension of the Hawk-Dove game, with the additional strategy Retaliator. Retaliators are just like Doves, except in contests against Hawks. When playing against Hawks, Retaliators behave like Hawks. A possible payoff matrix for this symmetric game is the following:
| Hawk (H) | Dove (D) | Retaliator (R) | |
| Hawk (H) | -1 | 2 | -1 |
| Dove (D) | 0 | 1 | 1 |
| Retaliator (R) | -1 | 1 | 1 |
Let us consider the population game where agents are matched to play the normal form game with payoffs as above.[1] The only Evolutionarily Stable State (ESS; see Thomas (1984) and Sandholm (2010a, section 8.3)) of this population game is the state (½H + ½D), with half the population playing Hawk and the other half playing Dove (Maynard Smith, 1982, appendix E; Binmore, 2013). Also, note that Retaliators are weakly dominated by Doves: they get a strictly lower expected payoff than Doves in any situation, except in those population states with no Hawks whatsoever (at which retaliators get exactly the same payoff as Doves).
Figure 1 below shows the best response correspondence of this game. Population states are represented in a simplex, and the color at any population state indicates the strategy that provides the highest expected payoff at that state: orange for Hawk, green for Dove, and blue for Retaliator. As an example, the population state where the three strategies are equally present, i.e. (⅓H + ⅓D +⅓R), which lies at the barycenter of the simplex, is colored in green, denoting that the strategy that provides the highest expected payoff at that state is Dove.

We would like to study the dynamic stability of the unique ESS (½H + ½D) in spatial contexts. In unstructured populations, ESSs are asymptotically stable under a wide range of revision protocols (see e.g. Sandholm (2010a, theorem 8.4.7)), and in particular under the best response rule. Therefore, one might be tempted to think that in our spatial model with the imitate the best neighbor rule (including some noise to allow for the occasional entry of any strategy), simulations will tend to spend most of the time around the unique (½H + ½D) and Retaliators would hardly be observed. This hypothesis may be further supported by the fact that the area around the unique ESS where Retaliators are suboptimal is quite sizable. In no situation can Retaliators obtain a higher expected payoff than Doves, and departing from the unique ESS, at least one half of the population would have to be replaced (i.e. all the Hawks) for Retaliators to get the same expected payoff as Doves.
Having seen all this, it may come as no surprise that if we simulate this game with the random-matching model we implemented in Part II, retaliators tend to disappear from any interior population state. The following video shows an illustrative simulation starting from a situation where all agents are retaliators (and including some noise to allow for the entry of any strategy).[2]
So, will space give Retaliators any chance of survival? Let’s build a model to explore this question!
3. Description of the model
The model we are going to develop here is a generalization of the model implemented in the previous chapter. The new model will have a new parameter, payoffs, that the user can set to input a payoff matrix of the form [ [A00 A01 … A0n] [A10 A11 … A1n] … [An0 An1 … Ann] ], containing the payoffs Aij that an agent playing strategy i obtains when meeting an agent playing strategy j (i, j ∈ {0, 1, …, n}). The number of strategies will be inferred from the number of rows in the payoff matrix.
The user will also be able to set any initial conditions using parameter n-of-players-for-each-strategy, which will be a list of the form [a0 a1 … an], where item ai is the initial number of agents playing strategy i. Naturally, the sum of all the elements in this list should equal the number of patches in the world.
Everything else stays as described in the previous chapter.
 4. Interface design
4. Interface design
We depart from the model we developed in the previous chapter (so if you want to preserve it, now is a good time to duplicate it).

The new interface (see figure 2 above) requires the following modifications:
- Remove the sliders for parameters CC-payoff, CD-payoff, DC-payoff, DD-payoff, and initial-%-of-C-players. Since these sliders were our way of declaring the corresponding global variables, you will now get all sorts of errors, but don’t panic, we will sort them out later.
- Remove the button labeled . Yes, more errors, but let us do our best to stay calm; we will fix them in a little while.
- Add an input box for parameter payoffs.
Create an input box with associated global variable payoffs. Set the input box type to “String (reporter)” and tick the “Multi-Line” box. Note that the content of payoffs will be a string (i.e. a sequence of characters) from which we will have to extract the payoff numeric values.
- Create an input box to let the user set the initial number of players using each strategy.
Create an input box with associated global variable n-of-players-for-each-strategy. Set the input box type to “String (reporter)”.
- Remove the “pens” in the Strategy Distribution plot. Since the number of strategies is unknown until the payoff matrix is read, we will need to create the required number of “pens” in the Code tab.
Edit the Strategy Distribution plot and delete both pens.
- We have also modified the monitor. Before it showed the ticks and now it shows the number of players (i.e. the value of a global variable named n-of-players, to be defined shortly). You may want to do this or not, as you like.
5. Code
5.1. Skeleton of the code

5.2. Global variables and individually-owned variables
First of all, we declare the global variables that we are going to use and we have not already declared in the interface. We will be using a global variable named payoff-matrix to store the payoff values on a list. It will also be handy to have a variable store the number of strategies and another variable store the number of players. Since this information will likely be used in various procedures and will not change during the course of a simulation, it makes sense to define the new variables as global. The natural names for these two variables are n-of-strategies and n-of-players:
globals [ payoff-matrix n-of-strategies n-of-players ]
Now we focus on the patches-own variables. We are going to need each individual patch to store its strategy and its strategy-after-revision. These two variables replace the previous C-player? and C-player?-after-revision. Thus, the code for patches-own variables looks as follows now:
patches-own [ ;; C-player? <== no longer needed ;; C-player?-after-revision <== no longer needed strategy ;; <== new variable strategy-after-revision ;; <== new variable payoff my-nbrs-and-me my-coplayers n-of-my-coplayers ]
5.3. Setup procedures
The current setup procedure looks as follows:
to setup clear-all setup-players ask patches [update-color] reset-ticks end
Clearly we will have to keep this code, but additionally we will have to set up the payoffs and set up the graph (since the number of pens to be created depends on the payoff matrix now). To do this elegantly, we should create separate procedures for each set of related tasks; to setup-payoffs and to setup-graph are excellent names for these new procedures. Thus, the code of procedure to setup should include calls to these new procedures:
to setup clear-all setup-payoffs ;; <== new line setup-players setup-graph ;; <== new line reset-ticks update-graph ;; <== new line ask patches [update-color] end
Note that we have also included a call to another new procedure named to update-graph, to plot the initial conditions.[3] The code of procedure to setup in this model looks almost identical to the code of the same procedure in the model we developed in Part II. As a matter of fact, we will be able to reuse much of the code we wrote for that model. Let us now implement procedures to setup-payoffs, to setup-graph and to update-graph. We will also have to modify procedures to setup-players and to update-color.
to setup-payoffs
The procedure to setup-payoffs will include the instructions to read the payoff matrix, and will also set the value of the global variable n-of-strategies. Looking at the implementation of the same procedure in the model we developed in Part II, can you implement procedure to setup-payoffs for our new model?
Implementation of procedure to setup-payoffs.
Yes, well done! We can use exactly the same code!
to setup-payoffs set payoff-matrix read-from-string payoffs set n-of-strategies length payoff-matrix end
to setup-players
The current procedure to setup-players looks as follows:
to setup-players ask patches [ set payoff 0 set C-player? false set C-player?-after-revision false set my-nbrs-and-me (patch-set neighbors self) set my-coplayers ifelse-value self-matching? [my-nbrs-and-me] [neighbors] set n-of-my-coplayers (count my-coplayers) ] ask n-of (round (initial-%-of-C-players * count patches / 100)) patches [ set C-player? true set C-player?-after-revision true ] end
This procedure will have to be modified substantially. In particular, the lines in bold in the code above include variables that do not exist anymore. But don’t despair! Once again, to modify procedure to setup-players appropriately, the implementation of the same procedure in the model we developed in Part II will be invaluable. Using that code, can you try to implement procedure to setup-players in our new model?
Implementation of procedure to setup-players.
The lines marked in bold below are the only modifications we have to make to the implementation of this procedure from Part II.
to setup-players let initial-distribution read-from-string n-of-players-for-each-strategy if length initial-distribution != length payoff-matrix [ user-message (word "The number of items in\n" "n-of-players-for-each-strategy (i.e. " length initial-distribution "):\n" n-of-players-for-each-strategy "\nshould be equal to the number of rows\n" "in the payoff matrix (i.e. " length payoff-matrix "):\n" payoffs ) ]
ask patches [set strategy false] let i 0 foreach initial-distribution [ j -> ask n-of j (patches with [strategy = false]) [ set payoff 0 set strategy i set strategy-after-revision strategy set my-nbrs-and-me (patch-set neighbors self) set my-coplayers ifelse-value self-matching? [my-nbrs-and-me] [neighbors] set n-of-my-coplayers (count my-coplayers) ] set i (i + 1) ]
set n-of-players count patches end
Finally, it would be a nice touch to warn the user if the total number of players in list n-of-players-for-each-strategy is not equal to the number of patches. One possible way of doing this is to include the code below, right before setting the patches’ strategies to false.
if sum initial-distribution != count patches [ user-message (word "The total number of agents in\n" "n-of-agents-for-each-strategy (i.e. " sum initial-distribution "):\n" n-of-players-for-each-strategy "\nshould be equal to the number of patches (i.e. " count patches ")" ) ]
to setup-graph
The procedure to setup-graph will create the required number of pens –one for each strategy– in the Strategy Distribution plot. Looking at the implementation of the same procedure in the model we developed in Part II, can you implement procedure to setup-graph for our new model?
Implementation of procedure to setup-graph.
Yes, well done! We can use exactly the same code!
to setup-graph set-current-plot "Strategy Distribution" foreach (range n-of-strategies) [ i -> create-temporary-plot-pen (word i) set-plot-pen-mode 1 set-plot-pen-color 25 + 40 * i ] end
to update-graph
Procedure to update-graph will draw the strategy distribution using a stacked bar chart, just like in the model we implemented in Part II (see figure 3 in chapter II-2). This procedure is called at the end of setup to plot the initial distribution of strategies, and will also be called at the end of procedure to go, to plot the strategy distribution at the end of every tick.
Looking at the implementation of the same procedure in the model we developed in Part II, can you implement procedure to update-graph for our new model?
Implementation of procedure to update-graph.
Yes, well done! We only have to replace the word players in the previous code with patches in the current code.
to update-graph let strategy-numbers (range n-of-strategies) let strategy-frequencies map [ n -> count patches with [strategy = n] / n-of-players ] strategy-numbers set-current-plot "Strategy Distribution" let bar 1 foreach strategy-numbers [ n -> set-current-plot-pen (word n) plotxy ticks bar set bar (bar - (item n strategy-frequencies)) ] set-plot-y-range 0 1 end
to update-color
Note that in the previous model, patches were colored according to the four possible combinations of values of C-player? and C-player?-after-revision. Now that there can be many strategies, it seems more natural to use one color for each strategy. It also makes sense to use the same color legend as in the Strategy Distribution plot (see procedure to setup-graph). Can you try and implement the new version of to update-color?
Implementation of procedure to update-color.
Here we go!
to update-color
set pcolor 25 + 40 * strategy
end
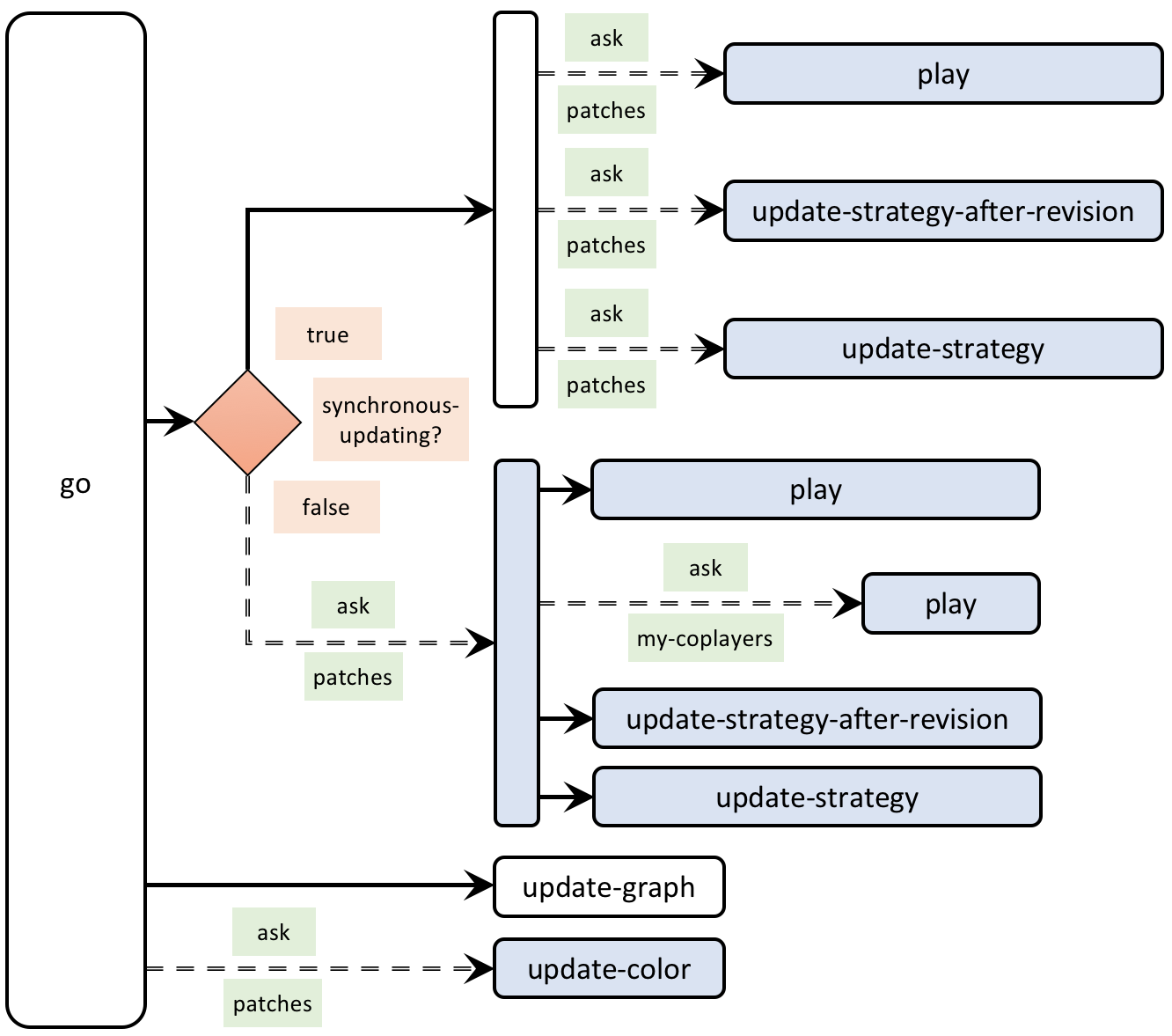
5.4. Go procedure
The current go procedure looks as follows:
to go ifelse synchronous-updating? [ ask patches [ play ] ask patches [ update-strategy-after-revision ;; here we are not updating the agent's strategy yet update-color ] ask patches [ update-strategy ] ;; now we update every agent's strategy at the same time ] [ ask patches [ play ask my-coplayers [ play ] ;; since your coplayers' strategies or ;; your coplayers' coplayers' strategies ;; could have changed since the last time ;; your coplayers played update-strategy-after-revision update-color update-strategy ] ] tick end
In the previous version of the model, the call to update-color had to be done in between the calls to update-strategy-after-revision and update-strategy. Now that the patches’ color only depends on their (updated) strategy, we should ask patches to run update-color at the end of procedure to go, after every patch has updated its strategy.
Finally, recall that we also have to run update-graph at the end of procedure to go, to plot the strategy distribution at the end of every tick. Thus, the code of procedure to go will be as follows:
to go
ifelse synchronous-updating?
[
ask patches [ play ]
ask patches [ update-strategy-after-revision ]
;; here we are not updating the agent's strategy yet
ask patches [ update-strategy ]
;; now we update every agent's strategy at the same time
]
[
ask patches [
play
ask my-coplayers [ play ]
;; since your coplayers' strategies or
;; your coplayers' coplayers' strategies
;; could have changed since the last time
;; your coplayers played
update-strategy-after-revision
update-strategy
]
]
tick
update-graph ;; <== new line
ask patches [update-color] ;; <== new line
end
5.5. Other procedures
to play
In procedure to play the patch has to compute its payoff. For that, the patch must count how many of its coplayers are using each of the possible strategies. We can count the number of coplayers that are using strategy i ∈ {0, 1, …, (n-of-strategies – 1)} as:
count my-coplayers with [strategy = i]
Thus, we just have to run this little function for each value of i ∈ {0, 1, …, (n-of-strategies – 1)} . This can be easily done using primitive n-values:
n-values n-of-strategies [ i -> count my-coplayers with [strategy = i] ]
The code above produces a list with the number of coplayers that are using each strategy. Let us store this list in local variable n-of-coplayers-with-strategy-?:
let n-of-coplayers-with-strategy-? n-values n-of-strategies [ i -> count my-coplayers with [strategy = i] ]
Now note that the relevant row of the payoff-matrix is the one at position strategy. We store this row in local variable my-payoffs:
let my-payoffs (item strategy payoff-matrix)
Finally, the payoff that the patch will get for each coplayer playing strategy i is the i-th element of the list my-payoffs, so we only have to multiply the two lists (my-payoffs and n-of-coplayers-with-strategy-?) element by element, and add up all the elements in the resulting list. To multiply the two lists element by element we use primitive map:
sum (map * my-payoffs n-of-coplayers-with-strategy-?)
With this, we have finished the code in procedure to play.
to play let n-of-coplayers-with-strategy-? n-values n-of-strategies [ i -> count my-coplayers with [strategy = i] ] let my-payoffs (item strategy payoff-matrix) set payoff sum (map * my-payoffs n-of-coplayers-with-strategy-?) end
to update-strategy-after-revision
Right now, procedure to update-strategy-after-revision is implemented as follows:
to update-strategy-after-revision set C-player?-after-revision ifelse-value (random-float 1 < noise) [ one-of [true false] ] [ [C-player?] of one-of (my-nbrs-and-me with-max [payoff]) ] end
What changes do we have to make in this procedure?
Implementation of procedure to update-strategy-after-revision.
The only changes we have to make are highlighted in bold below:
to update-strategy-after-revision set strategy-after-revision ifelse-value (random-float 1 < noise) [ random n-of-strategies ] [ [strategy] of one-of (my-nbrs-and-me with-max [payoff]) ] end
to update-strategy
Right now, procedure to update-strategy is implemented as follows:
to update-strategy set C-player? C-player?-after-revision end
What changes do we have to make in this procedure?
Implementation of procedure to update-strategy.
Keep up the excellent work!
to update-strategy
set strategy strategy-after-revision
end
5.6. Complete code in the Code tab
The Code tab is ready!
globals [ payoff-matrix n-of-strategies n-of-players ] patches-own [ strategy strategy-after-revision payoff my-nbrs-and-me my-coplayers n-of-my-coplayers ] to setup clear-all setup-payoffs setup-players setup-graph reset-ticks update-graph ask patches [update-color] end to setup-payoffs set payoff-matrix read-from-string payoffs set n-of-strategies length payoff-matrix end to setup-players let initial-distribution read-from-string n-of-players-for-each-strategy if length initial-distribution != length payoff-matrix [ user-message (word "The number of items in\n" "n-of-players-for-each-strategy (i.e. " length initial-distribution "):\n" n-of-players-for-each-strategy "\nshould be equal to the number of rows\n" "in the payoff matrix (i.e. " length payoff-matrix "):\n" payoffs ) ]
if sum initial-distribution != count patches [ user-message (word "The total number of agents in\n" "n-of-agents-for-each-strategy (i.e. " sum initial-distribution "):\n" n-of-players-for-each-strategy "\nshould be equal to the number of patches (i.e. " count patches ")" ) ]
ask patches [set strategy false] let i 0 foreach initial-distribution [ j -> ask n-of j (patches with [strategy = false]) [ set payoff 0 set strategy i set strategy-after-revision strategy set my-nbrs-and-me (patch-set neighbors self) set my-coplayers ifelse-value self-matching? [my-nbrs-and-me] [neighbors] set n-of-my-coplayers (count my-coplayers) ] set i (i + 1) ] set n-of-players count patches end to setup-graph set-current-plot "Strategy Distribution" foreach (range n-of-strategies) [ i -> create-temporary-plot-pen (word i) set-plot-pen-mode 1 set-plot-pen-color 25 + 40 * i ] end to go ifelse synchronous-updating? [ ask patches [ play ] ask patches [ update-strategy-after-revision ] ;; here we are not updating the agent's strategy yet ask patches [ update-strategy ] ;; now we update every agent's strategy at the same time ] [ ask patches [ play ask my-coplayers [ play ] ;; since your coplayers' strategies or ;; your coplayers' coplayers' strategies ;; could have changed since the last time ;; your coplayers played update-strategy-after-revision update-strategy ] ] tick update-graph ask patches [update-color] end to play let n-of-coplayers-with-strategy-? n-values n-of-strategies [ i -> count my-coplayers with [strategy = i] ] let my-payoffs (item strategy payoff-matrix) set payoff sum (map * my-payoffs n-of-coplayers-with-strategy-?) end to update-strategy-after-revision set strategy-after-revision ifelse-value (random-float 1 < noise) [ random n-of-strategies ] [ [strategy] of one-of my-nbrs-and-me with-max [payoff] ] end to update-strategy set strategy strategy-after-revision end to update-graph let strategy-numbers (range n-of-strategies) let strategy-frequencies map [ n -> count patches with [strategy = n] / n-of-players ] strategy-numbers
set-current-plot "Strategy Distribution" let bar 1 foreach strategy-numbers [ n -> set-current-plot-pen (word n) plotxy ticks bar set bar (bar - (item n strategy-frequencies)) ] set-plot-y-range 0 1 end to update-color set pcolor 25 + 40 * strategy end
5.7. Code inside the plots
Note that we take care of all plotting in the update-graph procedure. Thus there is no need to write any code inside the plot. We could instead have written the code of procedure to update-graph inside the plot, but given that it is somewhat lengthy, we find it more convenient to group it with the rest of the code in the Code tab.
6. Sample runs
Now that we have implemented the model we can explore the dynamics of the spatial Hawk-Dove-Retaliator game! Will Retaliators survive in a spatial context? Let us explore this question using the parameter values shown in figure 2 above. Get ready… because the results are going to blow your mind!
Unbelievable! Retaliators do not only survive, but they are capable of taking over about half the population. Is this observation robust? If you modify the parameters of the model you will see that indeed it is. The following video shows an illustrative run with noise = 0.05, synchronous-updating? = false and self-matching? = false.
The greater level of noise means that more Hawks appear by chance. This harms Retaliators more than it harms Doves, but Retaliators still manage to stay the most prevalent strategy in the population. How can this be?
First, note that even though the state where the whole population is choosing Retaliator is not an ESS, it is a Neutrally Stable State (Sandholm, 2010a, p. 82). And, crucially, it is the only pure state that is Nash (i.e. the only pure strategy that is best response to itself). Note that in spatial contexts neighbors face similar situations when playing the game (since their neighborhoods overlap). Because of this, it is often the case that neighbors choose the same strategy, and therefore clusters of agents using the same strategy are common. In the Hawk-Dove-Retaliator game, clusters of Retaliators are more stable than clusters of Doves (which are easily invadable by Hawks) and also more stable than clusters of Hawks (which are easily invadable by Doves). This partially explains the amazing success of Retaliators in spatial contexts, even though they are weakly dominated by Doves.
7. Exercises
You can use the following link to download the complete NetLogo model: nxn-imitate-best-nbr.nlogo.

Exercise 1. Killingback and Doebeli (1996, pp. 1140-1) explore the spatial Hawk-Dove-Retaliator-Bully game, with payoff matrix:
[[ -1 2 -1 2]
[ 0 1 1 0]
[ -1 1 1 2]
[ 0 2 0 1]]
Do Retaliators still do well in this game?
Exercise 2. Explore the beautiful dynamics of the following monocyclic game (Sandholm, 2010a, example 9.2.2, pp. 329-30):
[[ 0 -1 0 0 1]
[ 1 0 -1 0 0]
[ 0 1 0 -1 0]
[ 0 0 1 0 -1]
[-1 0 0 1 0]]
Compare simulations with balanced initial conditions (i.e. all strategies approximately equally present) and with unbalanced initial conditions (e.g. only one strategy present at the beginning of the simulation). What do you observe?
Exercise 3. How can we parameterize our model to replicate the results shown in figure 4 of Killingback and Doebeli (1996, p. 1141)?
![]() Exercise 4. In procedure to play we compute the list with the number of coplayers that are using each strategy as follows:
Exercise 4. In procedure to play we compute the list with the number of coplayers that are using each strategy as follows:
n-values n-of-strategies [ i -> count my-coplayers with [strategy = i] ]
Can you implement the same functionality using the primitive map instead of n-values?
![]() Exercise 5. Reimplement the procedure to update-strategy-after-revision so the revising agent uses the imitative pairwise-difference rule adapted to networks, i.e. the revising agent looks at a random neighbor and copies her strategy only if the observed agent’s average payoff is higher than the revising agent’s average payoff; in that case, the revising agent switches with probability proportional to the payoff difference.
Exercise 5. Reimplement the procedure to update-strategy-after-revision so the revising agent uses the imitative pairwise-difference rule adapted to networks, i.e. the revising agent looks at a random neighbor and copies her strategy only if the observed agent’s average payoff is higher than the revising agent’s average payoff; in that case, the revising agent switches with probability proportional to the payoff difference.
- The payoff function of the associated population game is
 , where
, where  denotes the population state and
denotes the population state and  denotes the payoff matrix of the normal form game. This population game can be obtained by assuming that every agent plays with every other agent. ↵
denotes the payoff matrix of the normal form game. This population game can be obtained by assuming that every agent plays with every other agent. ↵ - The fact that the simulation tends to linger around the ESS is a coincidence, since the imitate if better rule depends only on ordinal properties of the payoffs. What is not a coincidence is that Retaliators (which are weakly dominated by Doves) are eliminated in the absence of noise (Loginov, 2021). ↵
- There is some flexibility in the order of the lines within procedure to setup. For instance, the call to procedure setup-graph could be made before or after executing reset-ticks. ↵
