
Additional Reading Materials
Chapter 8: Polymers
Ch8.1 Addition Polymers: Polyethylene
Polymers (from Greek words poly meaning “many” and mer meaning “parts”) are large molecules made up of covalently-linked repeating units, referred to as monomers. Polymers can be natural (starch is a polymer of sugar residues and proteins are polymers of amino acids) or synthetic [like polyethylene, polyvinyl chloride (PVC), and polystyrene]. The variety of structures of polymers translates into a broad range of properties and uses that make them integral parts of our everyday lives. Adding functional groups to the structure of a polymer can result in significantly different properties.
Ethylene (the common industrial name for ethene, C2H4) is a basic raw material in the production of polyethylene and other important compounds. Over 135 million tons of ethylene were produced worldwide in 2010 for use in the polymer, petrochemical, and plastic industries. Ethylene is produced industrially in a process called cracking, in which the long hydrocarbon chains in a petroleum mixture are broken into smaller molecules.
An example of ethylene polymerization reaction is shown in Figure 1. The monomer ethylene is a gas at room temperature, but when polymerized, using a transition metal catalyst, it is transformed into a solid material made up of long chains of –CH2– units called polyethylene. Polyethylene is a commodity plastic used primarily for packaging (bags and films).
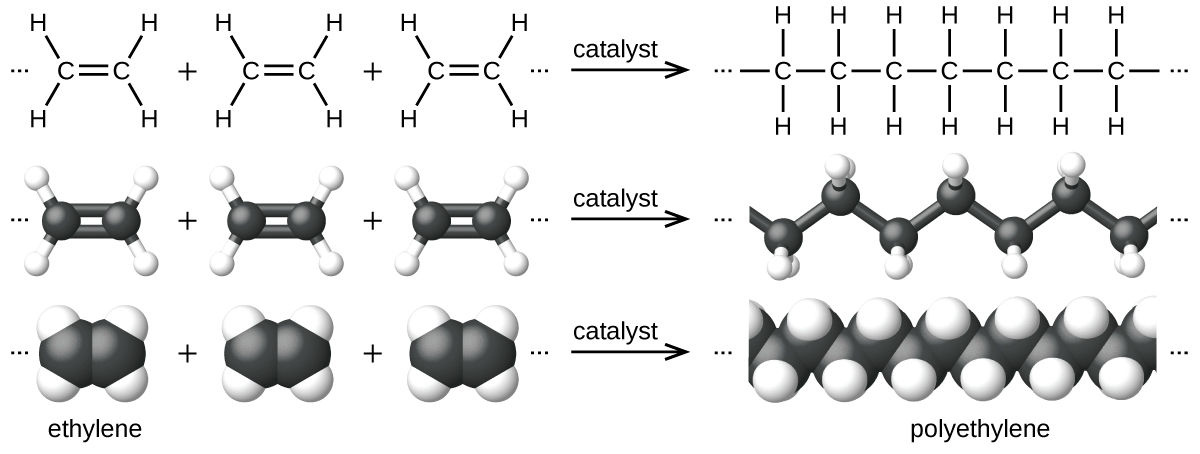
Addition polymers are usually made from a monomer containing a double bond, such as shown in Figure 1. We can think of the double bond as "opening out" in order to participate in two new single bonds in the following way:
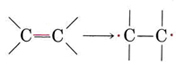
Thus, if ethylene is heated at moderate temperature and pressure in the presence of an appropriate catalyst, it polymerizes:

and forms polyethylene. In the complete polymer, all of the double bonds have been turned into single bonds. No atoms have been lost and you can see that the monomers have just been joined in the process of addition. The polymer at a molecular level consists of a collection of long-chain alkane molecules, most of which contain tens of thousands of carbon atoms. There is only an occasional short branch chain.
Many of polyethylene's properties are what we would expect from its molecular composition. The fact that it is a mixture of molecules each of slightly different chain length (and hence slightly different melting point) explains why it softens over a range of temperatures rather than having a single melting point. Because the molecules are only held together by dispersion forces, melting and softening occurs at relatively low temperatures considering the very long chain lengths (some of the cheaper varieties of polyethylene with shorter chains and more branch chains will even soften in boiling water), and polyethylene is soft and easy to scratch.
Dispersion forces also explains why different types of polyethylene have different properties.
The first commercial polyethylene process used peroxide catalysts at a temperature of 500 °C and 1000 atmospheres of pressure. This yields a transparent polymer with highly branched chains which do not pack together well and is low in density, and it is called LDPE (Low Density Polyethylene). The looser packing leads to weaker dispersion forces, and LDPE makes a flexible plastic. Today most LDPE is used for blow-molding of films for packaging and trash bags and flexible snap-on lids.
An alternate method is to use Ziegler-Natta aluminum titanium catalysts to make polyethylene with very little branching, allowing the polymer strands to pack closely, and thus it is high density and called HDPE (High Density Polyethylene). The tighter packing leads to stronger dispersion forces, and HDPE is three times stronger than LDPE and more opaque. About 45% of the HDPE is blow molded into milk and disposable consumer bottles. HDPE is also used for crinkly plastic bags to pack groceries at grocery stores.
Recycling Plastics
Polyethylene is a member of one subset of synthetic polymers classified as plastics. Plastics are synthetic organic solids that can be molded; they are typically organic polymers with high molecular masses. Most of the monomers that go into common plastics (ethylene, propylene, vinyl chloride, styrene, and ethylene terephthalate) are derived from petrochemicals and are not very biodegradable, making them candidate materials for recycling. Recycling plastics helps minimize the need for using more of the petrochemical supplies and also minimizes the environmental damage caused by throwing away these nonbiodegradable materials.
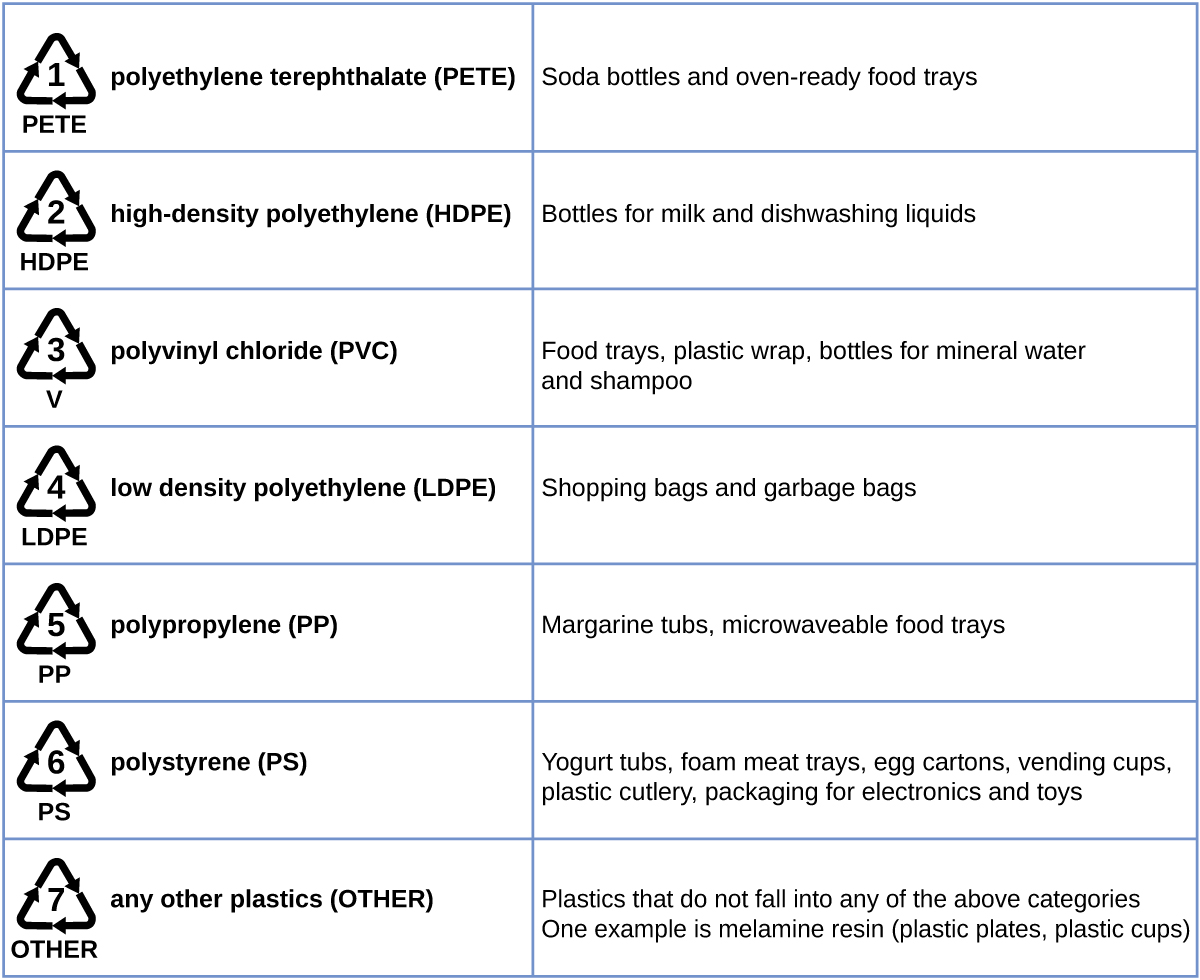
Plastic recycling is the process of recovering waste, scrap, or used plastics, and reprocessing the material into useful products. For example, polyethylene terephthalate (soft drink bottles) can be melted down and used for plastic furniture, in carpets, or for other applications. Other plastics, like polyethylene (bags) and polypropylene (cups, plastic food containers), can be recycled or reprocessed to be used again. Many areas of the country have recycling programs that focus on one or more of the commodity plastics that have been assigned a recycling code. These operations have been in effect since the 1970s and have made the production of some plastics among the most efficient industrial operations today.
Ch8.2 Other Addition Polymers
Consider a polymer made of a tangle of molecules with long linear chains of atoms. If the intermolecular forces between the chains are small and the material is subjected to pressure, the molecules will tend to move past one another in what is called plastic flow. Such a polymer usually is soluble in solvents that will dissolve short-chain molecules with chemical structures similar to those of the polymer. If the intermolecular forces between the chains are sufficiently strong to prevent motion of the molecules past one another the polymer will be solid at room temperature, but will usually lose strength and undergo plastic flow when heated. Such a polymer is thermoplastic.
The table below lists some other well-known addition polymers and also some of their uses. You can probably find at least one example of each of them in your home. Many of these polymers derive from a monomer of the form
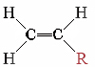
The resulting polymer thus has the general form

By varying the nature of the R group, the physical properties of the polymer can be controlled rather precisely.
| Monomer | Nonsystematic Name | Polymer | Some Typical Uses |
|---|---|---|---|
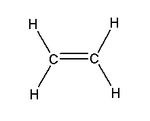 |
Ethylene | Polyethylene | Film for packaging and bags, toys, bottles, coatings |
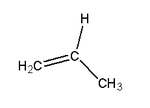 |
Propylene | Polypropylene | Milk cartons, rope, outdoor carpeting |
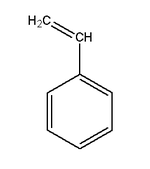 |
Styrene | Polystyrene | Transparent containers, plastic glasses, refrigerators, styrofoam |
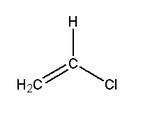 |
Vinyl chloride | Polyvinyl chloride, PVC | Pipe and tubing, raincoats, curtains, phonograph records, luggage, floor tiles |
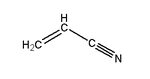 |
Acrylonitrile | Polyacrylonitrile (Orlon, Acrilan) | Textiles, ruga |
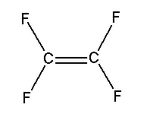 |
Tetrafluoroethylene | Teflon | Nonstick pan coatings, bearings, gaskets |
| H2C=CCl2 | Vinylidene dichloride | Saran | Clinging food wrap |
| H2C=CH(OCOCH3) | Vinyl acetate | Polyvinyl acetate | Elmer's glue - Silly Putty Demo |
| H2C=C(CH3)COOCH3 | Methyl methacrylate | Plexiglass, Lucite | Stiff, clear, plastic sheets, blocks, tubing, and other shapes |
- PVC (polyvinyl chloride), which is found in plastic wrap, simulated leather, water pipes, and garden hoses, is formed from vinyl chloride (H2C=CHCl).
- Polypropylene: In the reaction to make polypropylene (H2C=CHCH3), the polymer bonds are always through the carbons of the double bond. Carbon #3 (highlighted in red) already has saturated bonds and cannot participate in any new bonds. A methyl group is on every other carbon.
- Polystyrene: The reaction is the same for polystrene where every other carbon has a benzene ring attached. In the following illustrated example, many styrene monomers are polymerized into a long chain polystyrene molecule. The squiggly lines indicate that the polystyrene molecule extends further at both the left and right ends.
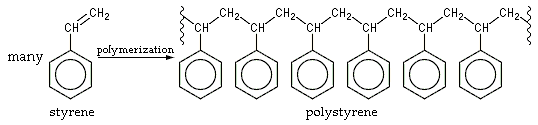
- Blowing fine gas bubbles into liquid polystyrene and letting it solidify produces expanded polystyrene, called Styrofoam by the Dow Chemical Company.
- Polystyrene with DVB: Cross-linking between polymer chains can be introduced into polystyrene by copolymerizing with p-divinylbenzene (DVB). DVB has vinyl groups (-CH=CH2) at each end of its molecule, each of which can be polymerized into a polymer chain like any other vinyl group on a styrene monomer.
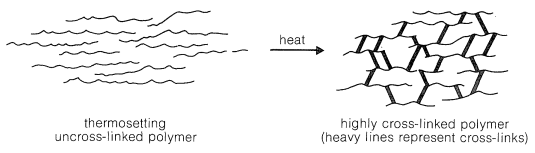
A cross-link is a chemical bond between polymer chains other than at the ends. Cross-links are extremely important in determining physical properties because they increase the molecular weight and limit the translational motions of the chains with respect to one another. Only two cross-links per polymer chain are required to connect all the polymer molecules in a given sample to produce one gigantic molecule. Only a few cross-links (Figure 2) reduce greatly the solubility of a polymer and tend to produce what is called a gel polymer, which, although insoluble, usually will absorb (be swelled by) solvents in which the uncross-linked polymer is soluble. The tendency to absorb solvents decreases as the degree of cross-linking is increased because the chains cannot move enough to allow the solvent molecules to penetrate between the chains.
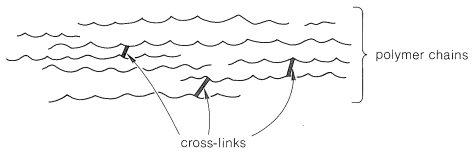
Thermosetting polymers normally are made from relatively low-molecular-weight, usually semifluid substances, which when heated in a mold become highly cross-linked, thereby forming hard, infusible, and insoluble products having a three-dimensional network of bonds interconnecting the polymer chains (Figure 3).
Addition polymers from conjugated dienes
Conjugated dienes (alkenes with two double bonds and a single bond in between) can be polymerized to form important compounds like rubber. This takes place, in different forms, both in nature and in the laboratory. Interactions between double bonds on multiple chains leads to cross-linkage which creates elasticity within the compound.
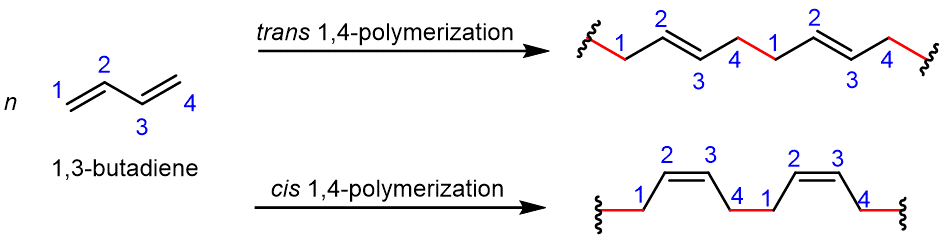
For rubber compounds to be synthesized, 1,3-butadiene must be polymerized. Figure 4 is a simple illustration of how this compound is formed into a chain. The 1,4-polymerization is much more useful to polymerization reactions, where a new σ covalent bond (highlighted in red) is formed between carbon 1 of one molecule and carbon 4 of another molecule. One of the π bonds is reacted in forming the new σ bond, the other π bond remains and is now between carbon 2 and carbon 3.
Natural rubber is an addition polymer that is obtained as a milky white fluid known as latex from a tropical rubber tree. Natural rubber is formed from the monomer isoprene (2-methyl-1,3-butadiene), where most of the double bonds in the polymer chain have the cis configuration, resulting in natural rubber's elastomer qualities.
Charles Goodyear accidentally discovered that by mixing sulfur and rubber, the properties of the rubber improved in being tougher, more resistant to heat and cold, and higher elasticity. This process was later called vulcanization after the Roman god of fire, and it works by forming cross-links between polymer chains via sulfur's reactions near the double bonds in the rubber. The development of vulcanized rubber for automobile tires greatly aided this industry.
Important conjugated dienes used in synthetic rubbers include isoprene (2-methyl-1,3-butadiene), 1,3-butadiene, and chloroprene (2-chloro-1,3-butadiene). Polymerized 1,3-butadiene is mostly referred to simply as polybutadiene. Polymerized chloroprene was developed by DuPont and given the trade name Neoprene. Cross-linkage between the chlorine atom of one chain and the double bond of another contributes to the overall elasticity of neoprene. This cross-linkage occurs as the chains lie next to each other at random angles, and the attractions between double bonds prevent them from sliding back and forth.
Copolymers
In a number of cases, monomers which are not dienes are also used for certain types of synthetic rubber, often copolymerized with dienes. Some of the most commercially important addition polymers are the copolymers. These are polymers made by polymerizing a mixture of two or more monomers. Such a polymer will be expected to have physical properties quite different from those of a mixture of the separate homopolymers. Many copolymers, such as ethene-propene, Viton rubbers, and Vinyon plastics are of considerable commercial importance.
styrene-butadiene rubber (SBR), which is a copolymer of 1,3-butadiene and styrene mixed in a 3 to 1 ratio, was developed during World War II when important supplies of natural rubber were cut off.
SBR is more resistant to abrasion and oxidation than natural rubber and can also be vulcanized. More than 40% of the synthetic rubber production is SBR and is used in tire production. A tiny amount is used for bubble-gum in the unvulcanized form. Other copolymer examples include nitrile rubber, which is copolymerized from butadiene and acrylonitrile (H2C=CHCN), and butyl rubber, which is copolymerized from isobutylene (H2C=C(CH3)2) and a small percentage of isoprene.
Ch8.3 Condensation Polymers
When addition polymers are formed, no by-products result. Formation of condensation polymers (also known as step-growth polymers) via condensation reactions, on the other hand, produces H2O, HCl, or some other simple molecule which escapes as a gas. A large number of important and useful polymeric materials are formed in this way from polyfunctional reactants. These polymerizations generally (but not always) combine two different components in an alternating structure. In contrast to chain-growth polymers, most of which grow by carbon-carbon bond formation, condensation polymers generally grow by carbon-heteroatom bond formation (e.g. C-O or C-N). Although polymers of this kind might be considered to be alternating copolymers, the repeating monomeric unit is usually defined as a combined moiety.
Polyesters
A polyester is a polymer where the individual units are held together by ester linkages.
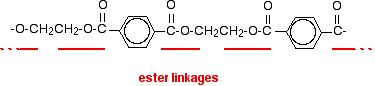
The usual name of this common polyester is poly(ethylene terephthalate). The everyday name depends on whether it is being used as a fibre or as a material for making things like bottles for soft drinks. When it is being used as a fiber to make clothes, it is often just called polyester. It may sometimes be known by a brand name like Terylene. When it is being used to make bottles, for example, it is usually called PET.
A polyester is made by a reaction involving an acid with two -COOH groups, and an alcohol with two -OH groups. The common polyester drawn above is formed from terephthalic acid (benzene-1,4-dicarboxylic acid) and ethylene glycol (ethane-1,2-diol):
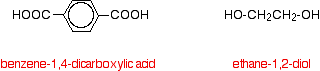
Now imagine lining these up alternately and making esters with each acid group and each alcohol group, losing a molecule of water every time an ester linkage is made, producing the chain shown above.
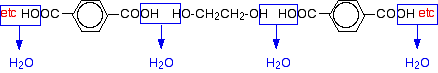
The presence of polar functional groups on the chains often enhances chain-chain attractions, and thereby crystallinity and tensile strength. Polyester molecules make excellent fibers and are used in many fabrics. A knitted polyester tube, which is biologically inert, can be used in surgery to repair or replace diseased sections of blood vessels. PET is used to make bottles for soda pop and other beverages. It is also formed into films called Mylar. When magnetically coated, Mylar tape is used in audio- and videocassettes. Synthetic arteries can be made from PET, polytetrafluoroethylene, and other polymers.
Polyamides
A familiar example of a polyamide, a polymer where the individual units are held together by amide linkages, is nylon, which is obtained from the reaction between 1,6-hexanediamine and adipic acid:
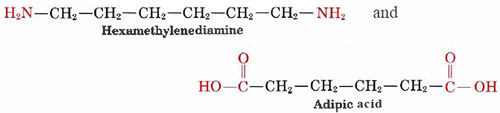
These two molecules can link up with each other because each contains a reactive functional group, either an amine or a carboxylic acid which react to form an amide linkage:
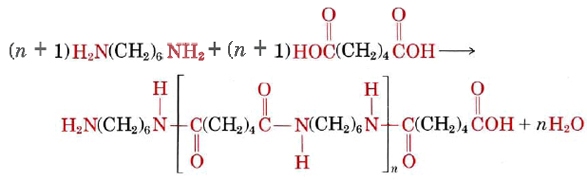
Nylon makes extremely strong threads and fibers because its long-chain molecules have dipole-dipole interaction and hydrogen bonding in addition to dispersion forces. Each N—H group in a nylon chain can hydrogen bond to the O of a C=O group in a neighboring chain, as shown below. Therefore the chains cannot slide past one another easily.
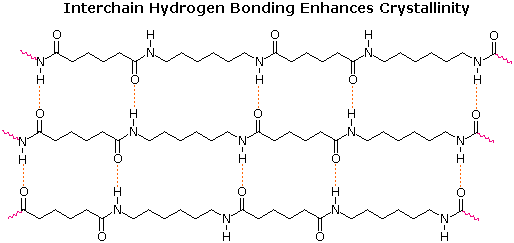
If you pull on both ends of a nylon thread, for example, it will only stretch slightly. After that it will resist breaking because a large number of hydrogen bonds are holding overlapping chains together. The same is not true of a polyethylene thread in which only dispersion forces attract overlapping chains together, and this is one reason that polyethylene is not used to make thread.
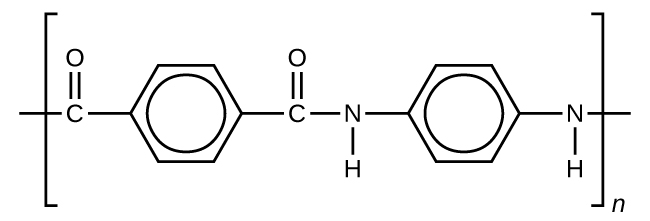
Kevlar (Figure 5) is a synthetic polymer made from two monomers 1,4-phenylene-diamine and terephthaloyl chloride (Kevlar is a registered trademark of DuPont). Kevlar’s first commercial use was as a replacement for steel in racing tires. Kevlar is typically spun into ropes or fibers. The material has a high tensile strength-to-weight ratio (it is about 5 times stronger than an equal weight of steel), making it useful for many applications from bicycle tires to sails to body armor.
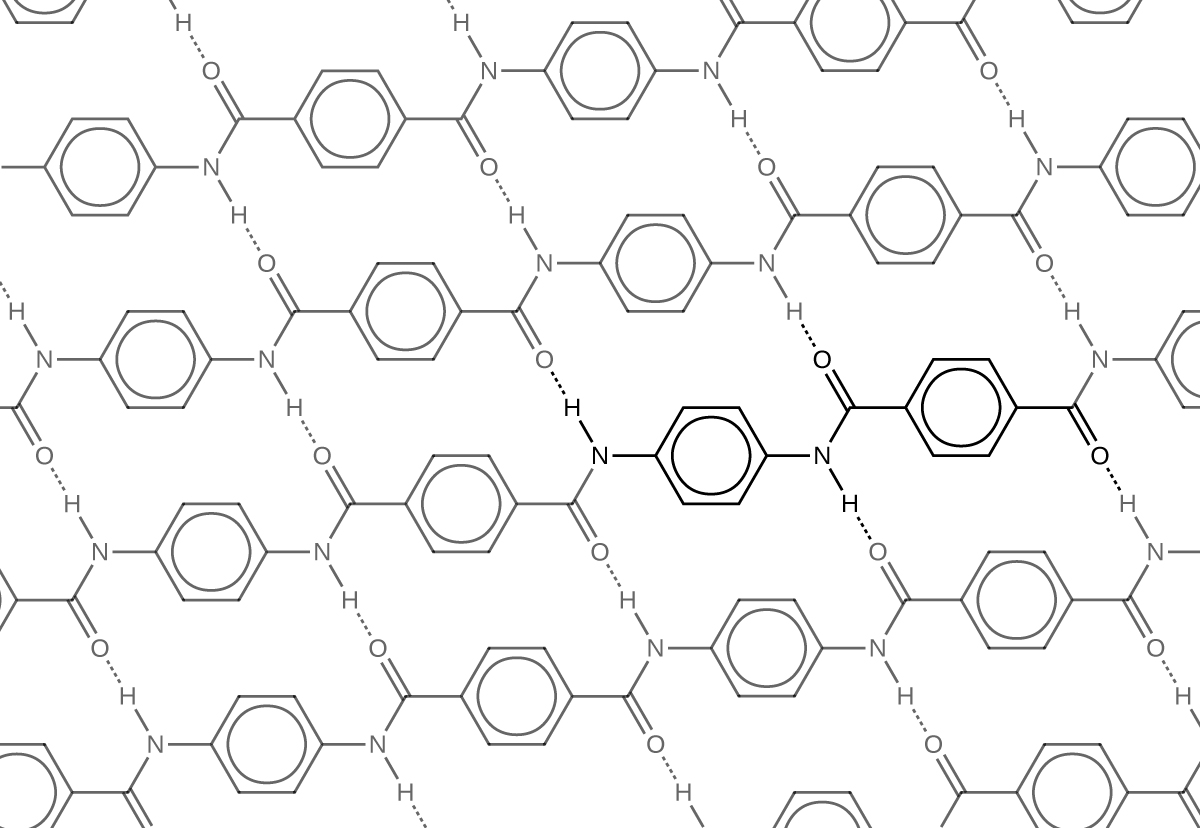
The material owes much of its strength to hydrogen bonds between polymer chains. These bonds form between the carbonyl group oxygen atom on one monomer and the hydrogen atom in the N–H bond of an adjacent monomer in the polymer structure (see dashed line in Figure 6). There is additional strength derived from the interaction between the unhybridized p orbitals in the benzene rings, called aromatic stacking.
Kevlar may be best known as a component of body armor, combat helmets, and face masks. Since the 1980s, the US military has used Kevlar as a component of the PASGT (personal armor system for ground troops) helmet and vest. Kevlar is also used to protect armored fighting vehicles and aircraft carriers. Civilian applications include protective gear for emergency service personnel such as body armor for police officers and heat-resistant clothing for fire fighters. Kevlar based clothing is considerably lighter and thinner than equivalent gear made from other materials (Figure 7).

In addition to its better-known uses, Kevlar is also often used in cryogenics for its very low thermal conductivity (along with its high strength). Kevlar maintains its high strength when cooled to the temperature of liquid nitrogen (–196 °C).
Ch8.4 Peptides
Chapter 8.4-8.7 are currently under construction. Please refer to “Chemistry: The Molecular Science” (5th ed. Moore and Stanitski) Chapter 7-7, Chapter 10-5c, and Chapter 10-7 for further reading.
Ch8.5 Proteins
Proteins and Enzymes
Proteins are large biological molecules made up of long chains of smaller molecules called amino acids. Organisms rely on proteins for a variety of functions—proteins transport molecules across cell membranes, replicate DNA, and catalyze metabolic reactions, to name only a few of their functions. The properties of proteins are functions of the combination of amino acids that compose them and can vary greatly. Interactions between amino acid sequences in the chains of proteins result in the folding of the chain into specific, three-dimensional structures that determine the protein’s activity.
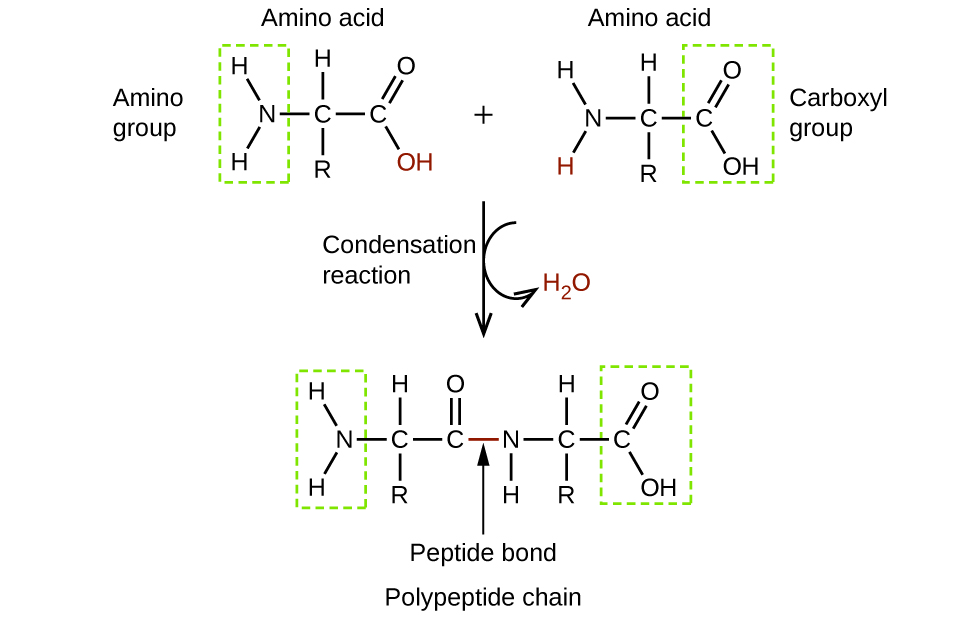
Amino acids are organic molecules that contain an amine functional group (–NH2), a carboxylic acid functional group (–COOH), and a side chain (that is specific to each individual amino acid). Most living things build proteins from the same 20 different amino acids. Amino acids connect by the formation of a peptide bond, which is a covalent bond formed between two amino acids when the carboxylic acid group of one amino acid reacts with the amine group of the other amino acid. The formation of the bond results in the production of a molecule of water (in general, reactions that result in the production of water when two other molecules combine are referred to as condensation reactions). The resulting bond—between the carbonyl group carbon atom and the amine nitrogen atom is called a peptide link or peptide bond. Since each of the original amino acids has an unreacted group (one has an unreacted amine and the other an unreacted carboxylic acid), more peptide bonds can form to other amino acids, extending the structure. (Figure 8) A chain of connected amino acids is called a polypeptide. Proteins contain at least one long polypeptide chain.
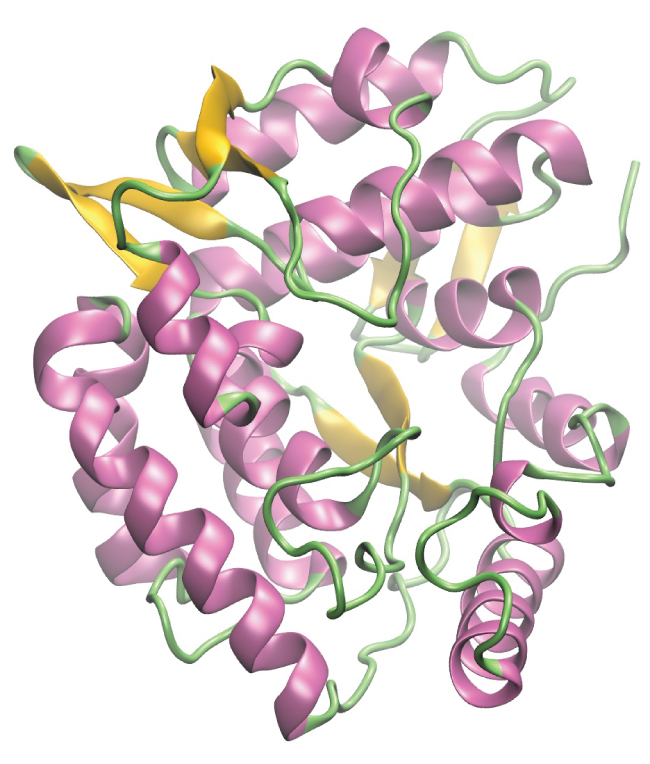
Enzymes are large biological molecules, mostly composed of proteins, which are responsible for the thousands of metabolic processes that occur in living organisms. Enzymes are highly specific catalysts; they speed up the rates of certain reactions. Enzymes function by lowering the activation energy of the reaction they are catalyzing, which can dramatically increase the rate of the reaction. Most reactions catalyzed by enzymes have rates that are millions of times faster than the noncatalyzed version. Like all catalysts, enzymes are not consumed during the reactions that they catalyze. Enzymes do differ from other catalysts in how specific they are for their substrates (the molecules that an enzyme will convert into a different product). Each enzyme is only capable of speeding up one or a few very specific reactions or types of reactions. Since the function of enzymes is so specific, the lack or malfunctioning of an enzyme can lead to serious health consequences. One disease that is the result of an enzyme malfunction is phenylketonuria. In this disease, the enzyme that catalyzes the first step in the degradation of the amino acid phenylalanine is not functional (Figure 9). Untreated, this can lead to an accumulation of phenylalanine, which can lead to intellectual disabilities.
Ch8.6 Lipids
Ch8.7 DNA
Hydrogen Bonding and DNA
Deoxyribonucleic acid (DNA) is found in every living organism and contains the genetic information that determines the organism’s characteristics, provides the blueprint for making the proteins necessary for life, and serves as a template to pass this information on to the organism’s offspring. A DNA molecule consists of two (anti-)parallel chains of repeating nucleotides, which form its well-known double helical structure, as shown in Figure 10.
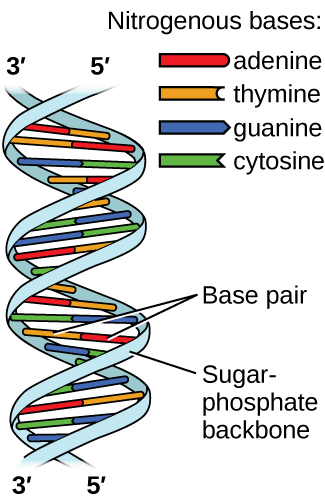
Each nucleotide contains a (deoxyribose) sugar bound to a phosphate group on one side, and one of four nitrogenous bases on the other. Two of the bases, cytosine (C) and thymine (T), are single-ringed structures known as pyrimidines. The other two, adenine (A) and guanine (G), are double-ringed structures called purines. These bases form complementary base pairs consisting of one purine and one pyrimidine, with adenine pairing with thymine, and cytosine with guanine. Each base pair is held together by hydrogen bonding. A and T share two hydrogen bonds, C and G share three, and both pairings have a similar shape and structure Figure 11.
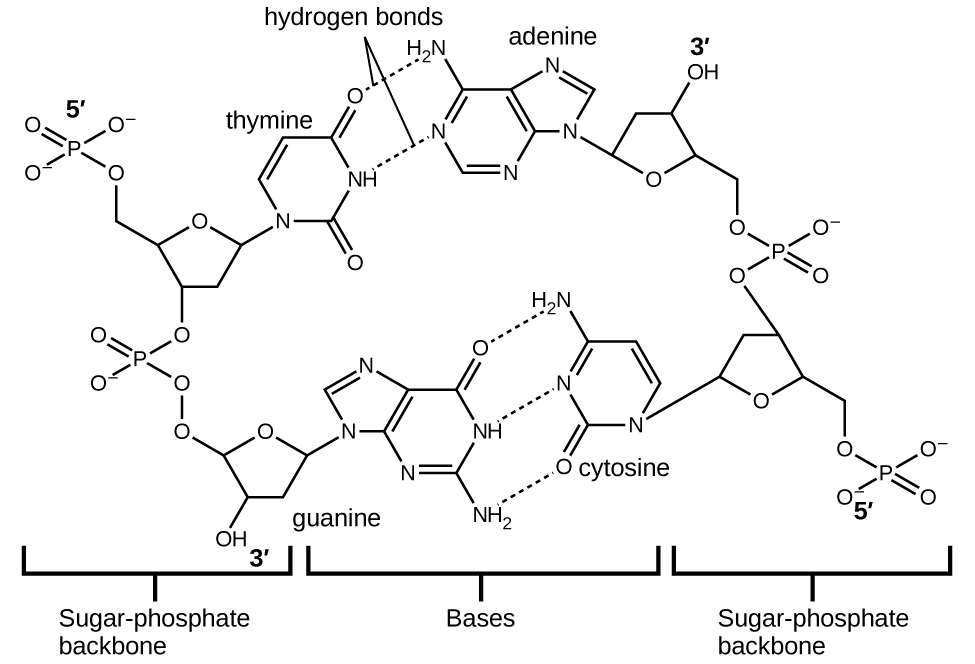
The cumulative effect of millions of hydrogen bonds effectively holds the two strands of DNA together. Importantly, the two strands of DNA can relatively easily “unzip” down the middle since hydrogen bonds are relatively weak compared to the covalent bonds that hold the atoms of the individual DNA molecules together. This allows both strands to function as a template for replication.
DNA in Forensics and Paternity
The genetic material for all living things is a polymer of four different molecules, which are themselves a combination of three subunits. The genetic information, the code for developing an organism, is contained in the specific sequence of the four molecules, similar to the way the letters of the alphabet can be sequenced to form words that convey information. The information in a DNA sequence is used to form two other types of polymers, one of which are proteins. The proteins interact to form a specific type of organism with individual characteristics.
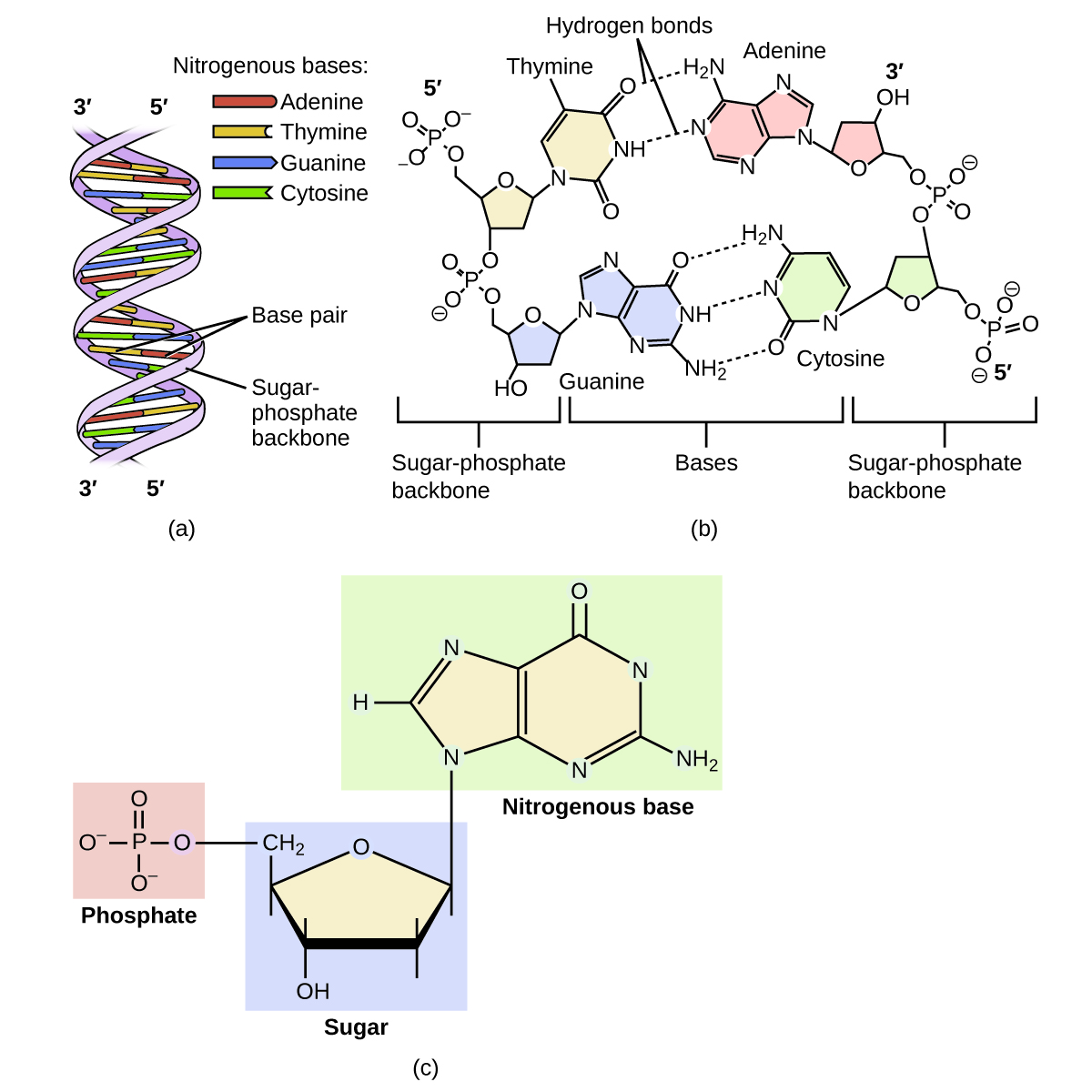
A genetic molecule is called DNA, which stands for deoxyribonucleic acid. The four molecules that make up DNA are called nucleotides. Each nucleotide consists of a single- or double-ringed molecule containing nitrogen, carbon, oxygen, and hydrogen called a nitrogenous base. Each base is bonded to a five-carbon sugar called deoxyribose. The sugar is in turn bonded to a phosphate group [latex](-\text{PO}_4^{\;\;3-})[/latex] When new DNA is made, a polymerization reaction occurs that binds the phosphate group of one nucleotide to the sugar group of a second nucleotide. The nitrogenous bases of each nucleotide stick out from this sugar-phosphate backbone. DNA is actually formed from two such polymers coiled around each other and held together by hydrogen bonds between the nitrogenous bases. Thus, the two backbones are on the outside of the coiled pair of strands, and the bases are on the inside. The shape of the two strands wound around each other is called a double helix (see Figure 12).
It probably makes sense that the sequence of nucleotides in the DNA of a cat differs from those of a dog. But it is also true that the sequences of the DNA in the cells of two individual pugs differ. Likewise, the sequences of DNA in you and a sibling differ (unless your sibling is an identical twin), as do those between you and an unrelated individual. However, the DNA sequences of two related individuals are more similar than the sequences of two unrelated individuals, and these similarities in sequence can be observed in various ways. This is the principle behind DNA fingerprinting, which is a method used to determine whether two DNA samples came from related (or the same) individuals or unrelated individuals.
Using similarities in sequences, technicians can determine whether a man is the father of a child (the identity of the mother is rarely in doubt, except in the case of an adopted child and a potential birth mother). Likewise, forensic geneticists can determine whether a crime scene sample of human tissue, such as blood or skin cells, contains DNA that matches exactly the DNA of a suspect.
Watch this video animation of how DNA is packaged for a visual lesson in its structure.
